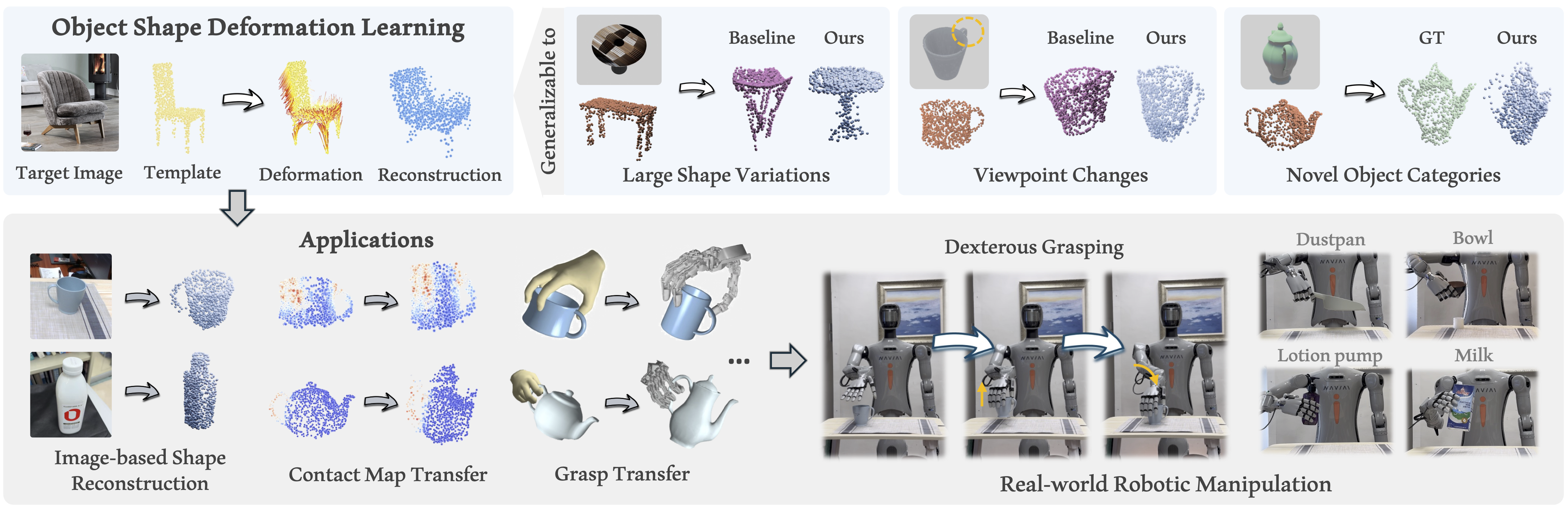
Figure 1. Our framework can handle large template–target shape variations, diverse viewpoints, and unseen categories, and supports downstream dexterous manipulation.
TL;DR: We present a generalizable deformation learning framework that leverages 2D foundation features to explicitly deform a category-level shape template for robust monocular 3D reconstruction.
Monocular 3D shape recovery is fundamental to geometric understanding, yet achieving robust generalization across arbitrary viewpoints and unseen object categories remains a significant challenge. In this paper, we present a generalizable deformation learning framework that reconstructs 3D objects by explicitly deforming a category-level shape template to match the target observation. To address complex shape variations between the template and the target, we introduce a geometry-guided feature modeling mechanism. This process first enriches foundation features with template topology to yield a geometry-aware representation, which is then explicitly correlated with the target observation to guide precise deformation. Furthermore, to bridge the disparity between the fixed template and arbitrary target views, we propose a view-adaptive feature aggregation module. This module leverages multi-view template features and their corresponding camera poses to enrich the canonical template representation, ensuring robust feature alignment regardless of the target's perspective. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art methods in handling large shape variations and diverse viewpoints, exhibiting strong generalization to novel categories and effectively supporting downstream real-world dexterous robotic manipulation tasks.
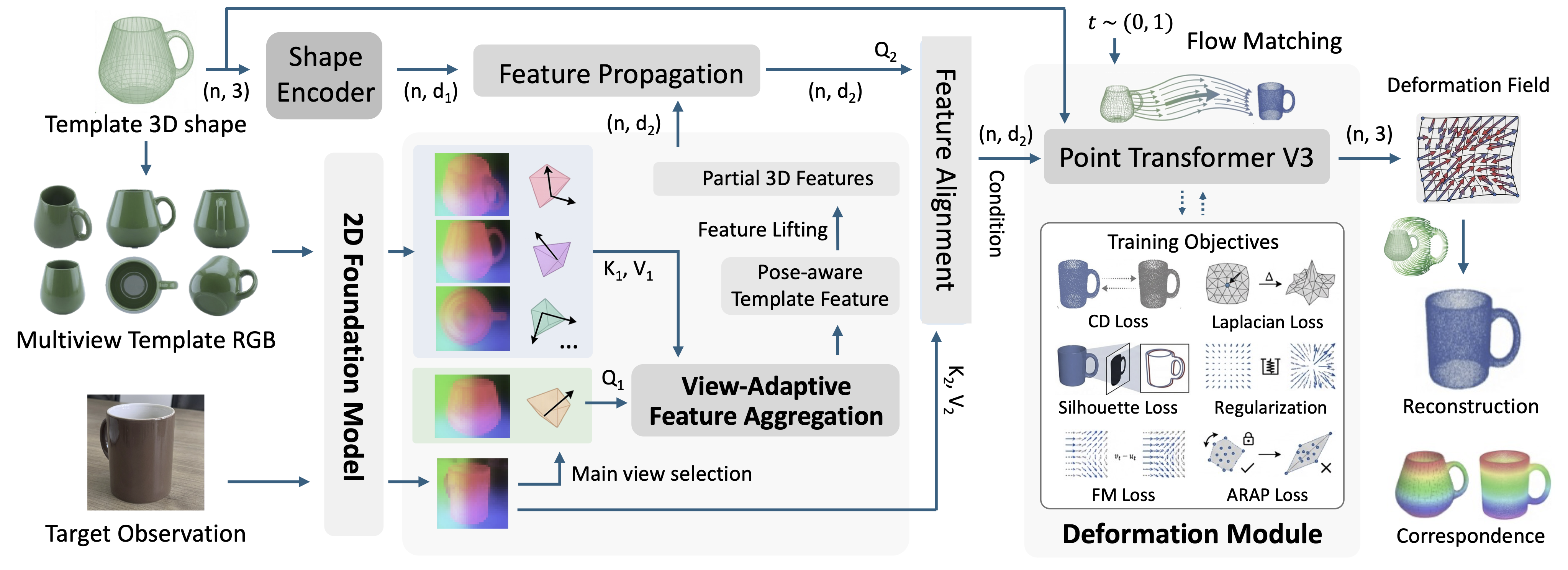
We formulate single-view reconstruction as geometry-guided shape deformation: given a target RGB image and a category-level 3D template, we predict a per-point deformation field that aligns the template with the observed shape using a conditional flow matching framework. This deformation is conditioned on the geometry-guided modeling of 2D foundation features of template and target observation. To ensure these features are spatially aligned and robust to varying observation angles, we introduce two key components: (1) a geometry-guided feature modeling process, which diffuses lifted 2D features across the 3D template surface to bridge the domain gap; and (2) a view-adaptive feature aggregation module, which synthesizes a pose-aware, viewpoint-invariant feature map to compensate for self-occlusions.
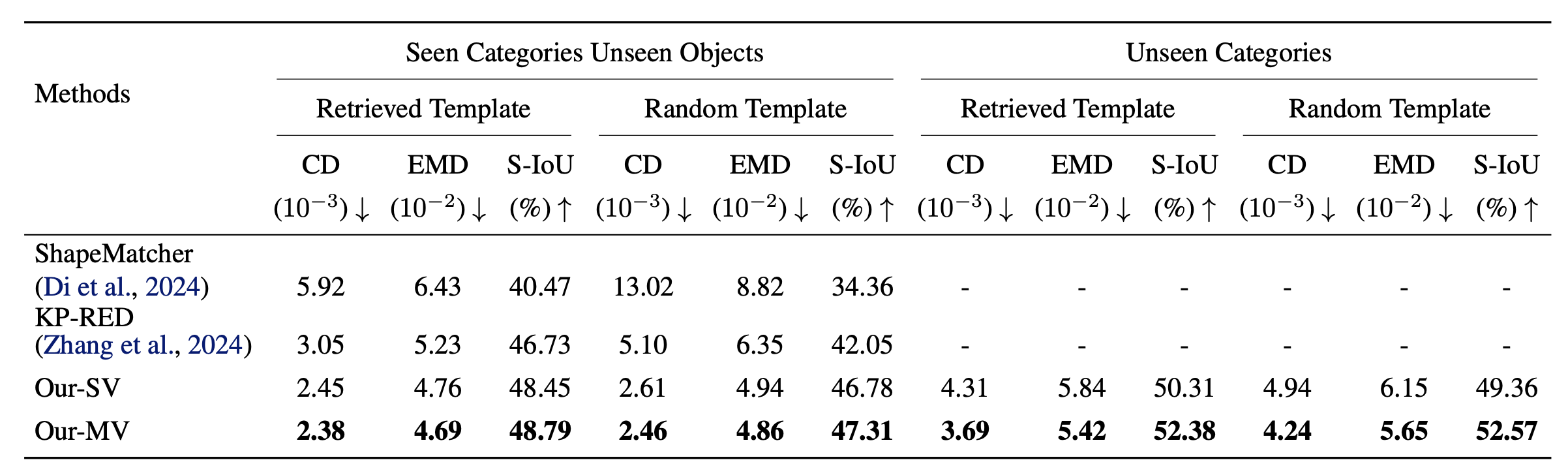
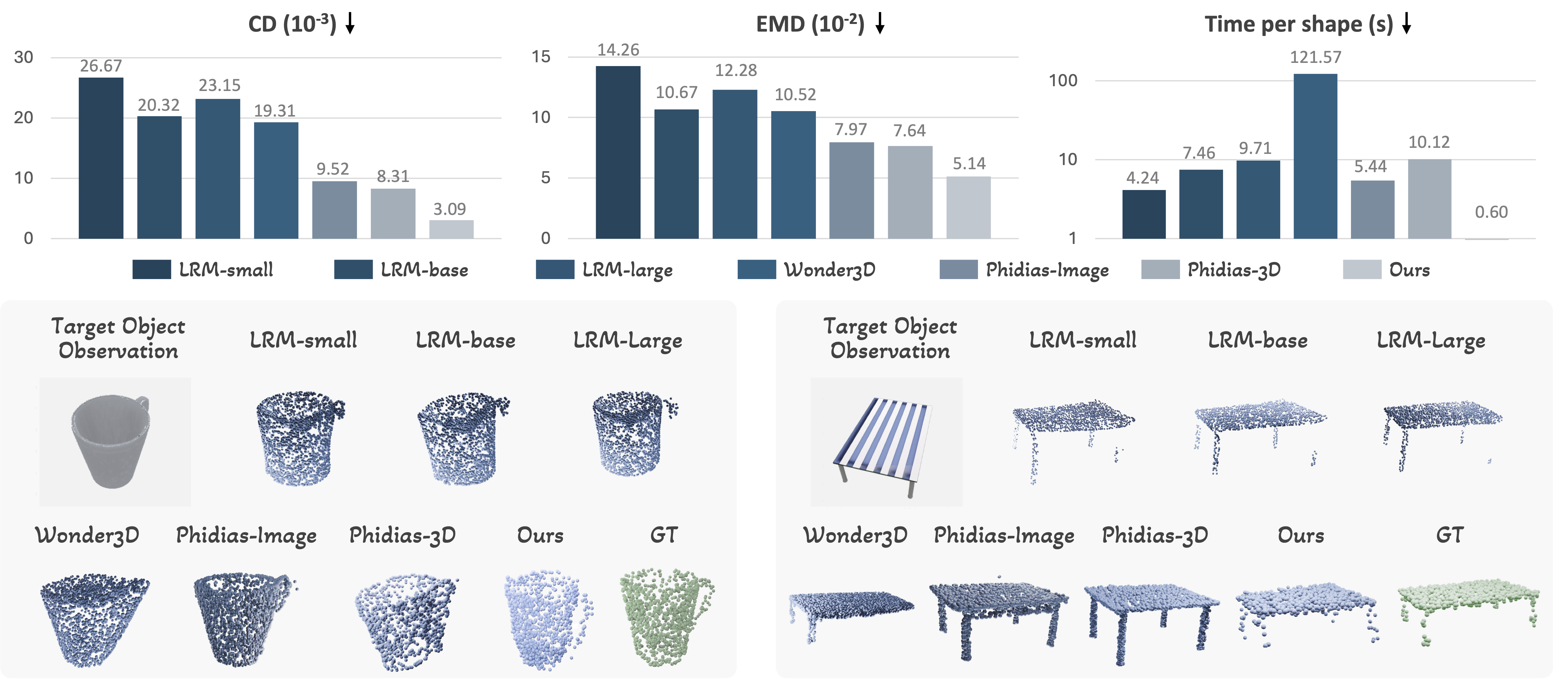
On both seen and unseen categories, our method achieves lower Chamfer distance and EMD and higher silhouette IoU than deformation baselines. Under the Random Template setting—where baselines degrade sharply—our geometry-guided modeling maintains performance similar to Retrieved Template, indicating robustness to large template–target variation.
Compared to large reconstruction models, our template deformation better preserves plausible structure under occlusion (e.g., mug handles, chair legs) by leveraging the template topology.
A distinct advantage of our deformation-based framework is the inherent preservation of dense point-wise correspondence, which naturally facilitates downstream tasks such as dexterous grasp transfer. We leverage the predicted deformation fields to warp contact maps from templates to novel targets, guiding the optimization of grasp configurations for arbitrary robotic hands. This transfer-based dexterous grasp generation process requires only about 0.67 s for deformation prediction and 15 s for contact-based grasp recovery. We further demonstrate the practical applicability of our approach through real-world physical experiments on a NAVIAI AW-1 humanoid robot.

If you find this work useful, please cite:
@inproceedings{ma2026godeform,
title = {Geometry-Guided Modeling of Foundation Features Enables Generalizable Object Shape Deformation Learning},
author = {Ma, Yiyao and Chen, Kai and Zhou, Zhongxiang and Song, Zhuheng and Xie, Dongsheng and Tan, Zelong and Xiong, Rong and Dou, Qi},
booktitle = {Proceedings of the International Conference on Machine Learning},
year = {2026}
}